We are in continuous interaction with machines, activities we do online and give any command to our phone, it comes up with a relevant answer and solves all our queries. Few questions become food for thought for our brain, that does machines or devices understand the language which we speak? We, humans, have defined languages to communicate with each other, with the help of which we can easily interpret the question. But devices fail to decode such text or words. There are a few ways of understanding them. They need the sentences separated into the numeric form for understanding and process towards the answers or results.
What is Bag of Words
For communication or for delivering the command from us to the machine, there is a process called Bag of Words, which breaks the words into numbers and helps the device to understand. BOW model is a depiction that converts text into fixed-length vectors by keeping the word count. In this, the counting of words or text is being done, based on the number of times the same word is mentioned in a document, and this process is referred to as vectorization.

The model of Bag of Words includes the pre-processing of the text/words into vector format, which is easily understandable by the machines. It keeps the count of the total number of occurrences of the words in a document/file. In other words, this procedure involves the extraction of features from the text file and then uses these features for training the algorithms of Machine Learning. It keeps the vocabulary of all the words which are there in the file. Irrelevant of the formation of the sentence or their grammar.
Application of Bag of Words
As a Bag of Words is related to the language part of the machine, it applies to the field of Natural Language Processing, Information seeker from any document file, and further classifications.

It follows the following steps:
Bag of Words Model Example
Let us have a look at the example which we all can easily relate to, as it is very much a part of our regular lives. Here is the example of Bag of words and for a better understanding of the concept. We all are always up for online shopping, highly rely on customer reviews for a product before we devote ourselves to buying it.
So, we will use this example here.
Here is an example of reviews about a fashion product:
- Review 1: This fashion product is useful and fancy
- Review 2: This fashion product is useful but not trending
- Review 3: This fashion product is awesome and fancy
We came across many such reviews related to the product and its features or fashion. There is a lot of understanding and insights we can extract from it and eventually predict if the product is worth buying or not. Now, the text is converted into the vector form, which is the conversion of the text into numbers. This is the simplest form of text presented in the numerical form without considering the grammar connecting words.

To start with the process, we will take all the featured words/ terminology from all the reviews above- consist of these 10 words: ‘this’, ‘product’, ‘is’, ‘useful’, ‘and’, ‘fancy’, ‘but’, ‘not’, ‘trending’, ‘awesome’.
Let us pre-process the reviews i.e., transform sentences into lower case alphabets, apply stemming and lemmatization, and remove stop words.
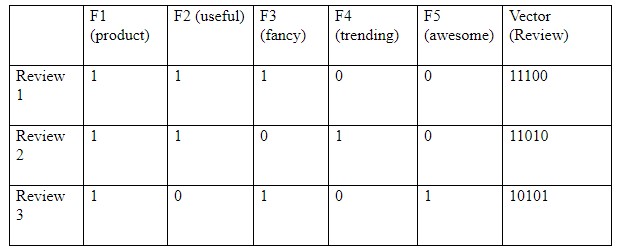
Now, we can mark the word rate with 1s and 0s which is revealed below:
Now the in the above table, where 1 denotes the existence of a word in the sentence review and 0 denotes its nonappearance.
From the above example, one can easily understand the concept and conclude that the Bag of words model, works when there is a presence of the featured word in the document. So, it does not deem the significance, framework, and order of the sentences. On the other hand, it gives the vision that similar documents will have word counts like each other.
Limitation of Bag of Words
Some pitfalls of Bag of Words model, due to which developers might choose using TF-IDF or word2vec when dealing with a bulk of data.
- The major challenge arises when the new sentences include new words. If such a scenario occurs, then the vocabulary will increase and so as the vector’s size.
- Related to the above point, the vectors would also contain many 0s, thus causing a scarce matrix (which is what we would avoid)
- Another very important factor that comes here is, we are ignoring the grammatical part of the document, no connecting word, no prepositions are being entertained in BOW. Also, not the order of the sentences is taken into consideration, from which we might not able to understand the intention and context of the sentence.
Pingback: 6 Ways Mobile App Can Boost ROI Of Your Business - Guest Posts Hub
Pingback: Bag of Words Using Python – A Beneficial Machine Learning Algorithm – Guest Posts Hub